
The distilled story of 25 studies.
Tuesday morning, 9:14 AM. In a small IoT startup in Ankara, Cenk, a senior firmware engineer, stares at his screen. He needs to set up DMA-based ADC sampling on an STM32 board. He asks Claude — the code arrives, compiles, flashes. Sensors produce data. Cenk smiles. The following week, twelve smart water meters in the field start freezing randomly. The culprit: a peripheral clock misconfiguration. The compiler couldn’t catch it; silicon did. Cenk looks at his dashboard and asks himself: is this tool actually speeding us up, or just making us feel fast?
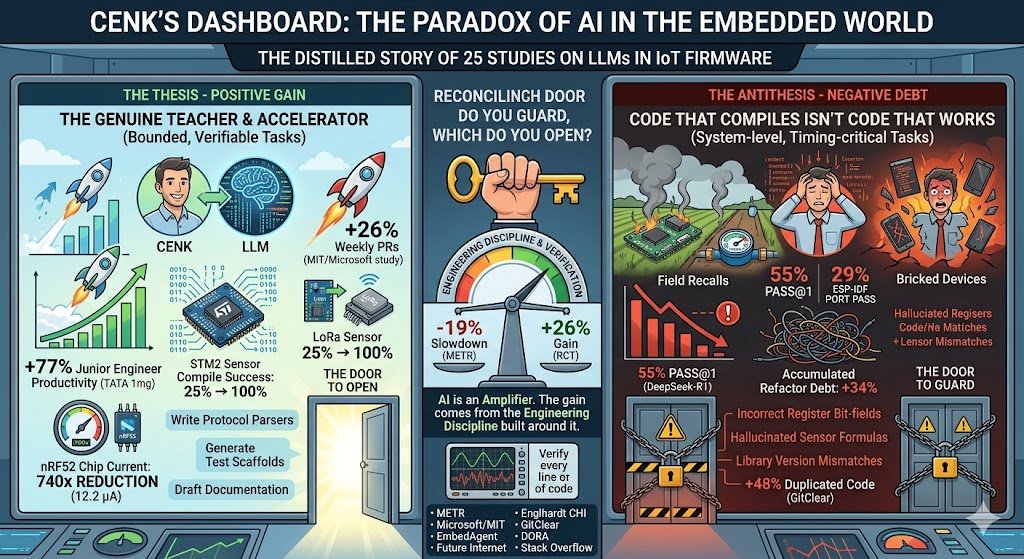
Cenk isn’t alone. Two of 2025’s most striking studies openly contradict each other. In METR’s controlled experiment, 16 experienced open-source developers took 19% longer to complete tasks when using AI tools — they had predicted a 24% speedup beforehand, and afterward still believed they had been 20% faster. That same year, a joint RCT by Microsoft, MIT, and Princeton with 4,867 developers measured a 26% increase in weekly PRs. Two studies, two opposite directions. Which one dominates in the embedded systems world?
The tool genuinely teaches, accelerates, democratizes
The evidence is strong. In the Englhardt study at CHI 2024, the human–AI workflow pushed LoRa sensor compilation success rates from 25% to 100% — even users with zero hardware experience could build working sensors. In the same study, GPT-4 reduced the nRF52 chip’s current draw by a factor of 740× through context-specific power optimization — down to 12.2 microamperes. In TATA 1mg’s year-long study of 300 engineers, junior developers saw productivity gains of up to 77%. Per DORA 2025, 90% of developers now use AI; 80% report positive productivity effects.
Code that compiles isn’t code that works
In the June 2025 EmbedAgent benchmark, DeepSeek-R1 achieved only 55% pass@1 across 126 embedded tasks; cross-platform porting dropped it to 29% on ESP-IDF. Even more striking: Claude-3.7-Thinking spent 78% of its reasoning tokens not on planning, but on fixing its own buggy code — the overthinking effect. A 2026 paper in Future Internet tested 27 LLMs on a full IoT stack (sensor → InfluxDB → Grafana); nearly all produced firmware that compiled but was hardware-wrong. Library version mismatches, incorrect register bit-fields, hallucinated sensor formulas.
The embedded world has a peculiarity: bugs live far away. In a web app, a bug refreshes the page; in firmware, a bug bricks ten thousand devices in the field. GitClear’s analysis of 211 million lines of code shows duplicated code rose 48% from 2020 to 2024; in AI-heavy repos, accumulated refactor debt is 34% higher. For IoT teams, this isn’t a luxury problem — memory is tight, battery is tight, OTA updates are expensive. Bloated code means shorter battery life means customer recalls. In the Stack Overflow 2025 survey, “actively distrust AI” jumped from 31% to 46%.
Which door do you guard, and which do you open?
Both sides are right — under different conditions. Here is the hypothesis that emerges from the intersection of five studies: LLMs deliver strong gains in IoT on bounded, verifiable, throwaway tasks. Write a protocol parser, generate a sensor calibration function, scaffold a regression test, draft documentation. Outside that boundary — system-level design, timing-critical routines, multi-component integration, safety-critical modules — capability collapses dramatically. The gain comes not from the tool but from the engineering discipline built around it. As DORA puts it: AI is an amplifier.
Cenk sits in the second field test the following Tuesday. This time, the team verifies every DMA line the LLM wrote on an oscilloscope. Two extra hours of work, cheaper than a week-long field recall. His dashboard is still open; productivity numbers are rising — this time slower, but durable. In 2026, the real question for IoT teams isn’t “should we use AI?” The real question is: which door do you guard, and which do you open? Because what separates −19% from +26% isn’t the model — it’s the discipline of using it.
Sources:
- METR arXiv:2507.09089
- Cui et al. Microsoft/MIT RCT
- EmbedAgent arXiv:2506.11003
- MDPI Future Internet 18(2):94
- Englhardt CHI EA 2024
- GitClear Code Quality Report 2025
- DORA 2025
- Stack Overflow Developer Survey 2025
- Khare et al. arXiv:2509.19708.